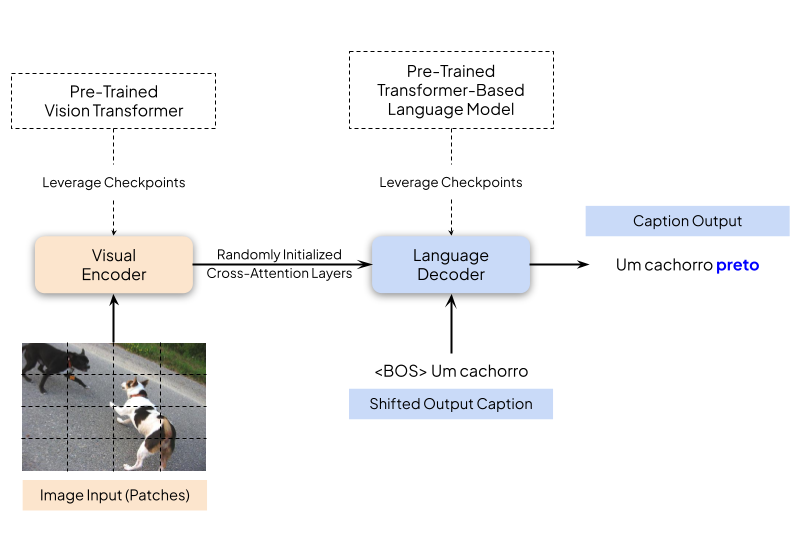
Image captioning refers to the process of creating a natural language description for one
or more images. This task has several practical applications, from aiding in medical diagnoses
through image descriptions to promoting social inclusion by providing visual context to people
with impairments.
Despite recent progress, especially in English, low-resource languages like Brazilian Portuguese
face a shortage of datasets, models, and studies. This work seeks to contribute to this context
by fine-tuning and investigating the performance of vision language models based on the
Transformer architecture in Brazilian Portuguese. We leverage pre-trained vision model
checkpoints (ViT, Swin, and DeiT) and neural language models (BERTimbau, DistilBERTimbau, and
GPorTuguese-2). Several experiments were carried out to compare the efficiency of different model
combinations using the #PraCegoVer-63K, a native Portuguese dataset, and a translated
version of the Flickr30K dataset.
The experimental results demonstrated that configurations using the Swin, DistilBERTimbau, and
GPorTuguese-2 models generally achieved the best outcomes. Furthermore, the #PraCegoVer-63K
dataset presents a series of challenges, such as descriptions made up of multiple sentences
and the presence of proper names of places and people, which significantly decrease the
performance of the investigated models.